How Torque's Bonding Operation Enables Self-Configuring Systems


In this multi-part series, we explore each aspect of Torque Framework and how, together, they form an entirely new way of managing cloud system architectures. For an overview of Torque Framework concepts, check out our documentation.
“Self-configuring” sounds impossible, we know. Anyone who has managed cloud deployments understands the devil is in the details. You can’t merely abstract them away. Besides, “abstractions are leaky,” as Joel Spolsky famously said. Even Infrastructure as Code leaks here and there, and it’s the best we have. Torque Framework, however, abstracts system parts and their relationships in several important ways that change the nature of how architectures and infrastructures relate. Allow me to explain.
Despite IaC, Infrastructure and Architecture are Still Tightly Coupled
Thanks to Infrastructure as Code solutions, the configurations we usually work with (HCL files, YAMLs and other scripts) are actually abstractions of cloud resource settings into files and templates that are easier to edit and distribute. Although far more efficient than purely manual processes, you still provision and manage infrastructure more or less in a direct fashion.
So, while Terraform HCLs and Kubernetes YAMLs conceptually separate systems from their underlying infrastructure, in practice, there is no separation. Don’t agree? Then migrate your system to a new cloud. Or migrate just a part of it to go multi-cloud. And do it this week. If a system cannot be implemented in a different manner without significant effort and cost, the abstractions that describe it cease to be meaningfully useful.
When viewed through this lens, with configurations playing a central role in cloud system management, and always at risk of configuration drift or error as architecture changes are made, there is no way to see how a system could configure itself. Only Platform as a Service solutions have managed to accomplish an abstraction which allows you to avoid touching or thinking about the infrastructure, but PaaS abstractions map resources one-to-one, so its usage is quite inflexible.
When designing a system and adding new services, there are always choices. Usually, more than one implementation COULD be used to make an abstract design concrete. Once you choose however, optionality quickly evaporates as the complexity of configurations grows.
Dependency Inversion: Depend Upon Abstractions, Not Concretions
Using Torque Framework, your single architecture design is the abstraction upon which all concretions (infrastructure implementations) depend, not the other way around. At the same time, your deployment options increase. Instead of making changes to every deployment by editing static configuration files, you use simple commands that modify your architecture dependency graph (DAG), from within your codebase.
Referencing the installed libraries that describe the components and links comprising your system design, Torque Framework uses another kind of entity called providers to turn each new change into concrete configurations across all the cloud deployments and development environments you specify. Just like components and links, you can install different open-source providers, fine-tune each to suit your own needs, or write your own from scratch. In this way, any configuration can be made to your exacting standards, and then updated across all your deployments, all at once.
This is crucial: Torque does not substitute manual or templated configuration changes for something pre-determined, like PaaS might, or generalized in a way that ignores system-critical details. When changes are applied, providers in the deployment layer have a special way to access and interpret necessary values from the DAG so that configurations become dynamic and responsive.
Bonding: How a DAG Transforms into Deployments
If components and links in the DAG describe what needs doing, and providers grant the means to do it through infrastructure, the Bonding Operation controls how, ensuring it happens the right way.
Every entity in the framework exposes its own interface. Components and links have interfaces, and so do providers. But because Torque is an open framework, to which anyone can add a library which describes an entity, it’s not possible to pre-plan for all potential pairings. The temptation might be to express more deployment specifics (configurations) via an interface, but that has the effect of tightly coupling two entities for a single use case. While certainly possible, Torque’s power lies in keeping each entity independent.
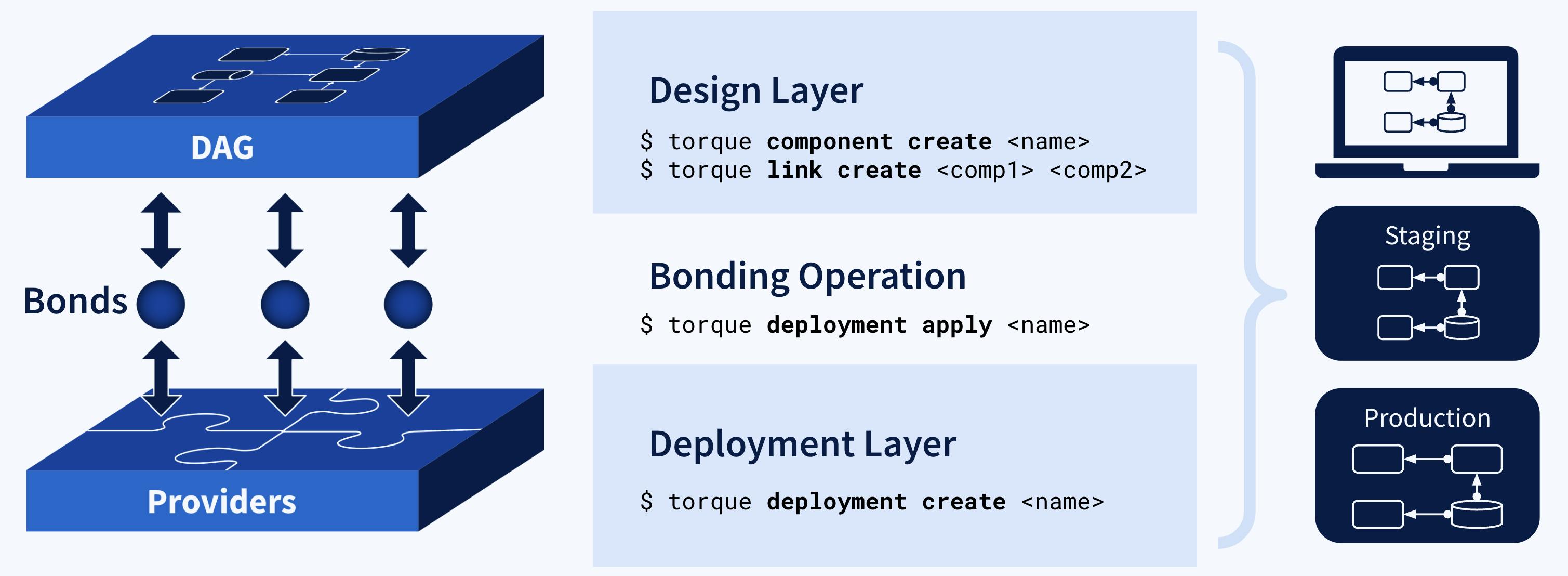
So, between the design layer, where the DAG lives, and the deployment layer, where providers are, Torque Framework uses entities called bonds to perform a Bonding Operation that gives otherwise incompatible components and providers the ability to work together. Through bonds, providers are able to reference the contextual information of their paired components within the DAG, and deploy effectively to their given instance.
The bonding operation allows components, links and providers to remain simple and self-contained, keeping dependencies properly inverted, while also retaining the ability to apply complex configuration information to the chosen infrastructure.
Remember, unlike today’s configuration files, which are scattered across deployments, Torque Framework keeps all system design information in the DAG– a single source of truth accessible to all developers. So there’s no reason to manually alter configurations anywhere but in the bond, since it automatically propagates to all deployments. Hence, every update of the architecture is self-configuring across deployments.
Over time, as more libraries are written and available for re-use, more developers will achieve self-configuring cloud systems with less and less manual input at the start. In the same way we stopped touching hardware, and then virtual machines and even cloud service consoles, configurations will fade into the background.